
In the transport industry, where safety and reliability are paramount, extracting accurate information from technical documentation can be the difference between efficient operations and costly manual effort.
Retrieval-Augmented Generation (RAG) has emerged as a useful approach for processing complex engineering manuals, maintenance documentation, and regulatory requirements. This post explores practical RAG for engineering document processing, optimised for transport industry applications.
Firstly, what’s so unique about engineering document processing that LLMs can’t deal with natively?
A major challenge in processing engineering documentation is handling the technical diagrams, schematics, and specification tables that are vital in transport applications.
Here’s how a typical engineering document makeup looks – a combination of text, tables, images, and almost always spanning across multiple pages.
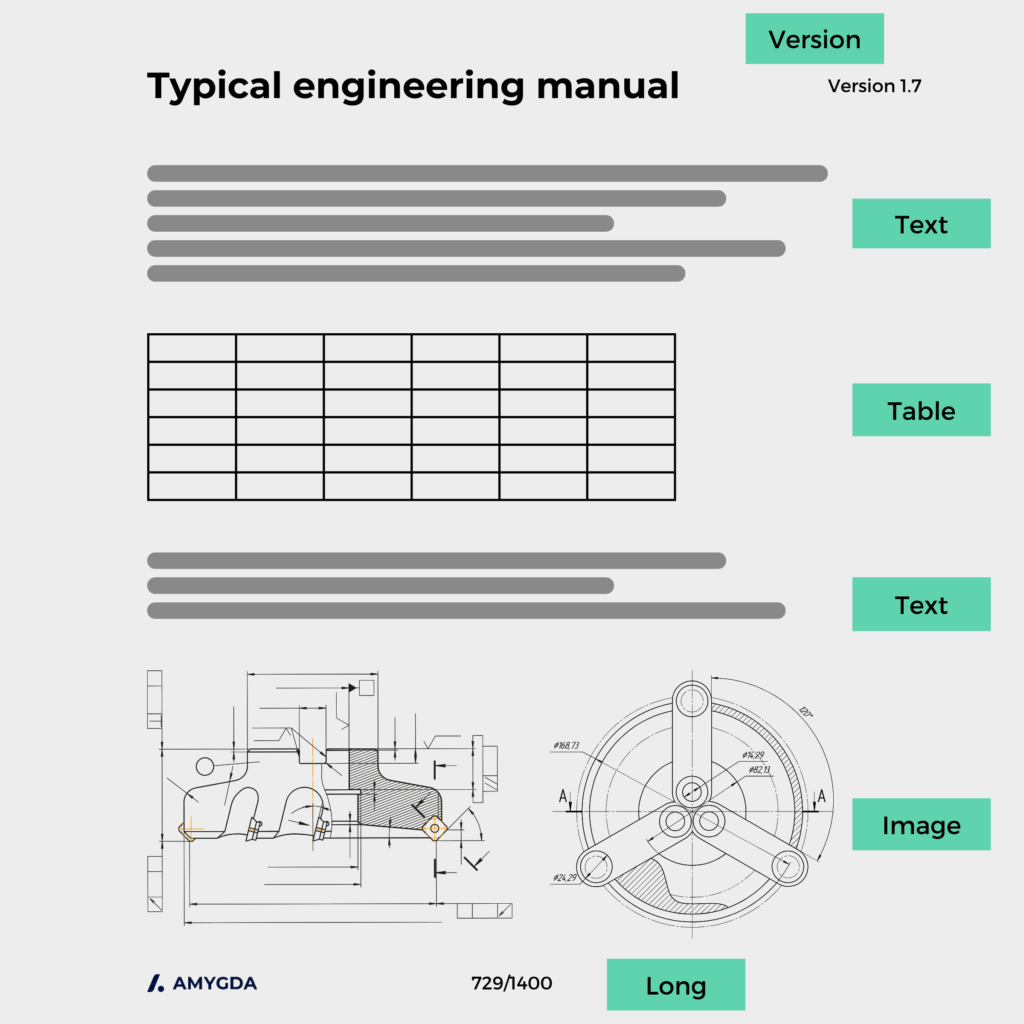
Transport documentation presents uniquely challenging characteristics:
- Dense technical content filled with industry jargon that general AI systems simply don’t understand
- Critical safety procedures scattered across multiple volumes, often referenced indirectly
- Intricate diagrams and tables that contain vital information but aren’t processed properly by standard document systems
- Maintenance history spanning decades with multiple equipment versions and modifications
When we started building RAG applications for engineering document processing in the transport industry, we quickly realised the vanilla RAG did not work for processing engineering applications.
Most text processing approaches treated these manuals like any other document, missing the crucial interconnections between systems and procedures.
Traditional (or vanilla, as I call them) document processing from Large Language Models (LLMs) often stripped away context, separating text from the technical diagrams that were essential for a robust answer.
The result? We started seeing half the information and in some cases embarrassing results where completeness just wasn’t great.
We understood why this was happening. But knew that in the transport industry for engineering applications this would not be acceptable.
We quickly set out to build an approach that preserves the relationships between text, diagrams, and tables while understanding the hierarchy of systems and subsystems that make up complex transport equipment.
We tested key RAG with particular attention to context, technical diagrams, system relationships.
Here’s what we found and how you can optimise RAG techniques for engineering document processing in transport industry applications.
Comparing RAG for Engineering Document Processing in Transport Applications
| Technique No. | Easy testing and Implementation | without langchain | Quite powerful but requires change in vector db | Amygda comments, worth trying? (no guarantees this is right, test at your own risk) |
| HyDE | yes | NA | NA | Yes – Requires LLM fine tuning. Better off when llm is fine tuned to domain so better hypothetic questions are generated |
| Adaptive | yes | NA | NA | Yes – Requires LLM fine tuning: Classification of query isn’t a requirement for us specifically and even after classifying, same issue with llm requiring better knowledge of domain to generate queries. Even if analytical it will still requires generation of questions. |
| Contextual Enrich | yes | NA | NA | Yes – Good approach but requires us to manage the initial k otherwise there is a risk of very high context provided to the LLM which might reduce quality of answer. We tried this. |
| Contextual Chunk | yes | – | Requires an update to the vector db to include chunk headers to the chunks for reranking | No – Not convinced whether this will work based on those descriptions. Can we do reranking directly? Does reranking benefit from this type of information? Not tried because this requires re-indexing stuff to a specific format |
| Corrective RAG | yes | NA | NA | No: Not relevant: Requires web to add relevant information. |
| Fusion | yes | – | Requires an update to the vector db to include the bm25 indexing. | No – Good approach but requires a better tokenization method for creating the bm25 index. But again performing the tokenization on the entire vector db requires more computation . Not tried because this requires re-indexing stuff to a specific format |
| Hierarchical | yes | – | Requires a change in the vector db to work with this. | Maybe – Similar parallels to RAPTOR or soft clustering. Could work well. Would prefer to try out soft clustering over this. Not tried because this requires re-indexing stuff to a specific format |
| Soft Clustering | yes | Requires a change in the vector db to work with this. | Maybe We tried this very early on a different exercise and the results weren’t any better than not using it. | |
| Propositions | yes | – | Requires vector db change. | No – Requires LLM fine tuning. Better off when llm is fine tuned to domain so better propositions are generated. |
| Query Transformations | yes | – | – | Maybe – Requires LLM fine tuning. Better off when llm is fine tuned to domain so better query rewriting are generated |
| Reliable RAG | yes | – | – | Yes – Requires good knowledge of the domain to make an assessment. Fine tuning of LLM required. There is a potential if higher original K (=15) is used, the answer might do better by picking the 6 or 10 sources from the smaller selection of 15. |
| Reranking | yes | – | – | Yes – requires LLM knowledge to rerank so would be better off fine tuning the LLM model There is a potential if higher original K (=15) is used, the answer might do better by picking the 6 or 10 sources from the smaller selection of 15. |
| RAG with Feedback | no | – | Yes. Requires a new framework for feedback. | No – Smart but requires a new framework. |
Let’s examine various RAG techniques and their applicability to document processing:
1. Hypothetical Document Embedding (HyDE)
Core Concept: Creates hypothetical documents that match the expected answer before performing similarity search.
Strengths:
- Bridges the gap between query and document distribution in vector space
- Can improve retrieval precision
Limitations:
- Relies heavily on prompt templates
- Struggles with domain-specific queries
- Requires LLM fine-tuning for optimal performance in specialised domains
Implementation Complexity: Medium (can use existing vector database)
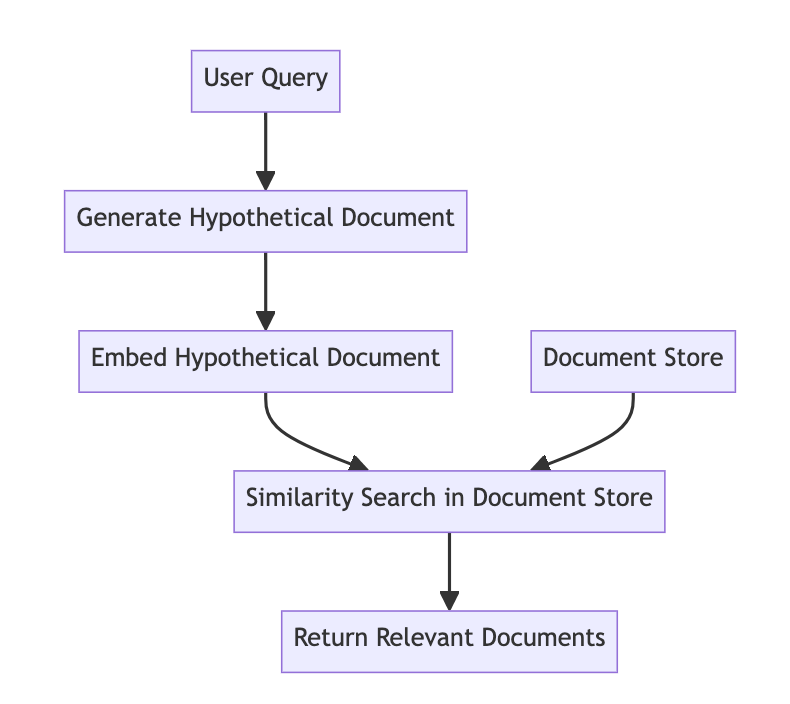
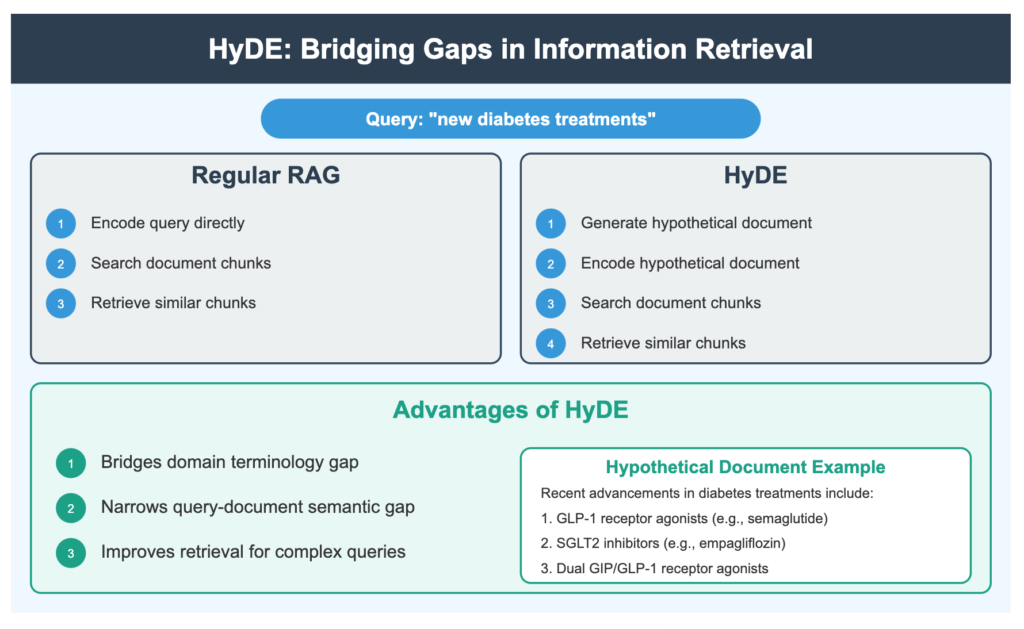
2. Adaptive Retrieval Augmented Generation
Core Concept: Classifies queries into four types (Factual, Analytical, Opinion, and Contextual) and applies tailored retrieval strategies.
Strengths:
- Adapts retrieval strategy based on query type
- Particularly effective for analytical queries requiring information from multiple sources
Limitations:
- Relies on LLM’s ability to generate appropriate sub-queries
- Challenging for domain-specific content
- Heavily dependent on prompt template strategies
Implementation Complexity: Medium (no configuration changes needed)
3. Context Enrichment Window
Core Concept: Attaches surrounding information to retrieve chunks to create expanded versions with preserved context.
Strengths:
- Preserves context that might be lost in traditional chunking
- Simple to implement
Limitations:
- Can introduce noise if neighboring content is irrelevant
- May increase token usage significantly
Implementation Complexity: Low (easiest to implement)
4. Contextual Chunk Headers
Core Concept: Adds headers to chunks using LLM and uses them for reranking.
Strengths:
- Provides better context for reranking algorithms
- Can improve precision
Limitations:
- Requires heavy API usage for header creation
- Needs vector database reconfiguration
Implementation Complexity: High (requires restructuring vector database)
5. Fusion Retrieval
Core Concept: Combines semantic search (vector database) and keyword search (BM25) with a weighting formula.
Strengths:
- Balances semantic understanding with keyword matching
- Can improve precision for technical terminology
Limitations:
- Complex tokenisation needed for tables and structured content
- Requires vector database reconfiguration
- Needs tuning of alpha hyperparameter
Implementation Complexity: High (requires implementing BM25)
6. Hierarchical Indices
Core Concept: Creates a two-tier retrieval system with document-level summaries and chunk-level details.
Strengths:
- Reduces search space
- Can improve retrieval efficiency
Limitations:
- Dependence on quality of summaries
- Risk of losing information if summaries don’t properly represent content
- Requires creation of new vector database structure
Implementation Complexity: High (requires restructuring vector database)
7. Query Transformations
Core Concept: Enhances queries through rewriting, step-back prompting, and sub-query decomposition.
Strengths:
- Makes queries more specific or generalises them as needed
- Breaks complex queries into manageable parts
Limitations:
- Relies on LLM’s domain understanding
- Similar to Adaptive RAG’s analytical technique
- Can fail if decomposition creates irrelevant sub-queries
Implementation Complexity: Medium (no configuration changes needed)
8. Reliable RAG
Core Concept: Filters irrelevant retrieved documents based on LLM judgment before answer generation.
Strengths:
- Reduces hallucinations
- Improves precision by filtering out irrelevant context
Limitations:
- Relies on LLM’s ability to judge document relevance
- May discard potentially useful information
- Most effective when chunking and embedding quality is already high
Implementation Complexity: Low (no configuration changes needed)
9. Reranking
Core Concept: Reranks retrieved documents using LLM or cross-encoders before answer generation.
Strengths:
- Addresses the limitation of pure cosine similarity
- Evaluates if documents answer the specific question
Limitations:
- Relies on LLM’s domain knowledge
- Requires additional computation step
Implementation Complexity: Low (no configuration changes needed)
10. RAG with Feedback Loop
Core Concept: Integrates user feedback to improve retrieval over time.
Strengths:
- Continuously improves with usage
- Adapts to user needs
Limitations:
- More complex implementation
- Benefits only visible after sustained usage
- Requires feedback collection and storage mechanisms
Implementation Complexity: Very high (requires new feedback framework)
11. Sparse Search
Core Concept: Utilises the sparse embedding to represent the high dimensional vector space with only few non zero entries for making efficient keyword search
Strengths:
- Address the limitations of shorter queries
Limitations:
- More complex implementation
- Benefits only for the shorter queries and keyword searched
Implementation Complexity: Very high (requires separate configuration of vector db)
12. DBSF (Distribution Based Score Fusion)
Core Concept: Utilises the sparse embedding and dense embedding in a hybrid fashion with a statistical method relied on gaussian distribution.
Strengths:
- Address the queries which requires both keyword and semantic search
Limitations:
- More complex implementation
- Benefits only when queries require both keyword and semantic
- Requires a change in vector database configuration to handle both configurations.
Implementation Complexity: Very high (requires change of vector db configuration)
Knowledge Graph Approaches
Beyond traditional RAG techniques, we explored knowledge graph approaches:
Summaries into Knowledge Graph (Raptor, Langchain, Neo4j)
Core Concept: Uses document summaries to create a knowledge graph representation.
Limitations:
- Graph creation is time-intensive (3+ hours for large documents)
- Neo4j struggles with large graphs
- Results underperformed compared to other RAG techniques
Hierarchical Map into Knowledge Graph
Core Concept: Leveraging the RAPTOR’S strategy for creating hierarchical summaries. Then utilising one of the level summaries to create a knowledge graph.
Advantages:
- Better preserves document structure
- More manageable graph creation
Limitations:
- Limited access to tabular data
- Inconsistent
- Difficult for page number mapping
Practical Recommendations
Based on our testing and analysis, we recommend considering these techniques for implementation:
- Context Enrichment Window – Easiest to implement with good results
- Reranking – Excellent balance of implementation simplicity and result quality
- Reliable RAG – Good for reducing hallucinations with minimal implementation effort
For organisations willing to invest more development resources:
- Fusion Retrieval – Worth exploring for technical documentation
- RAG with Feedback Loop – Consider for applications with consistent user base
What is the RAG approach Amygda uses for engineering document processing in transport industry?
Our exploration began with a ‘by-title’ strategy, which proved problematic for documents lacking structured titles. After evaluating multiple approaches (‘by-page’, ‘by-title’, ‘basic’, and ‘by-similarity’), we found that a ‘by-page’ similarity approach delivers optimal results by leveraging natural page breaks within documents.
Text Extraction and Processing Improvements
Our enhanced approach now:
- Generates individual text files for each document page
- Replaces images and tables with contextual summaries
- Processes entire pages where images/tables appear
- Utilises annotation boxes to highlight relevant elements
- Incorporates surrounding text for richer context
This ensures comprehensive information capture even when dealing with complex elements like system images and tables. If you want to know more about our approach and how this differs from the vanilla LLM chats you see out in open, drop me a line on [email protected].
Conclusion
The choice of RAG technique for document processing depends on your specific document types, query patterns, and implementation resources. Our exploration suggests that simpler techniques like Context Enrichment, Reranking, and Reliable RAG offer the best balance of implementation effort and result quality for most applications.
For domain-specific documents with technical terminology, consider investing in either fine-tuning your embedding models or implementing hybrid approaches like Fusion Retrieval.
As document processing technologies continue to evolve, combining multiple RAG techniques may ultimately yield the best results. Consider starting with simpler approaches and gradually incorporating more sophisticated techniques as your understanding of your specific document processing needs matures.
More resources
👉🏽 Level Up Your Skills: Join the Free 10-Day AI Agent Course!



