
Predictive maintenance in airports represents a fundamental shift from time-based interventions to condition-based strategies. For engineering and reliability teams managing complex airport infrastructure, the challenge lies not in collecting data—modern systems generate terabytes daily—but in extracting actionable insights that prevent failures before they impact operations.
The Evolution from Reactive to Predictive Maintenance
Traditional airport maintenance strategies typically follow manufacturer-recommended schedules or react to failures.
However, baggage handling systems (BHS), ground support equipment, and terminal assets operate under highly variable conditions, making fixed schedules suboptimal. Some components fail before scheduled maintenance, while others are serviced unnecessarily.
Predictive maintenance leverages real-time sensor data, event logs, and machine-learning algorithms to model equipment degradation patterns. This approach enables maintenance teams to intervene at the optimal moment, maximising asset life while minimising failure risk.
1. Data-Driven Monitoring: Beyond Simple Thresholds
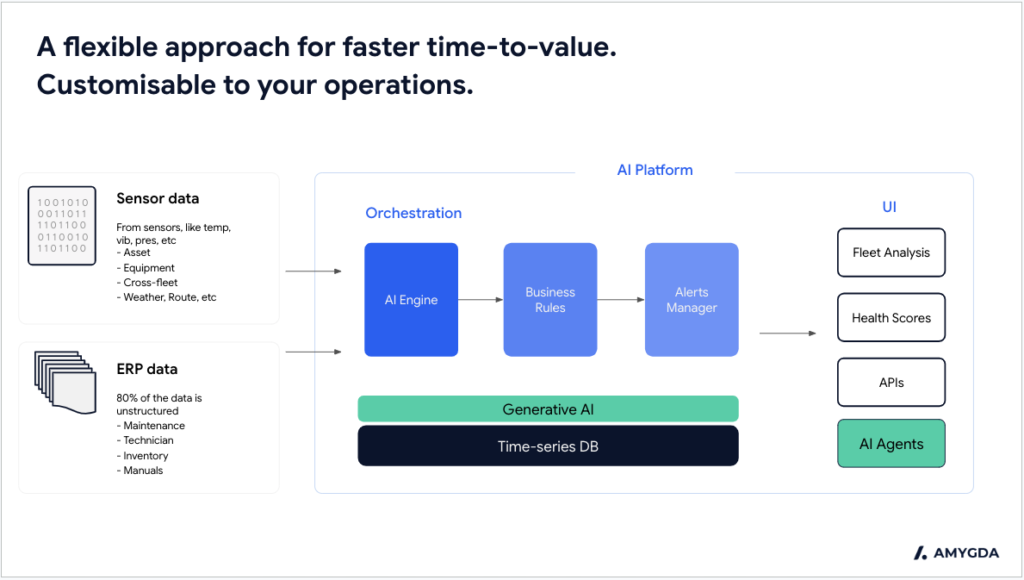
Modern platforms towards predictive maintenance for airports, must handle heterogeneous data sources across multiple OEM platforms.
A typical BHS installation might include conveyor systems from one vendor, sortation equipment from another, and screening machines from a third—each generating different data formats and frequencies.
We provide a good example of how AI is helping BHS monitoring.
The key to effective predictive maintenance lies in feature engineering and anomaly detection that works across these disparate systems. Rather than relying on pre-determined thresholds, advanced algorithms employ:
1/ Unsupervised Learning: Clustering techniques identify normal operating patterns without labelled failure data. By understanding what “normal” looks like across different operating conditions, the system can detect subtle deviations that precede failures
2/ Similarity Modeling: When historical run-to-failure data exists, similarity-based approaches compare current asset behaviour to past failure progressions. This enables remaining useful life (RUL) predictions based on actual degradation patterns rather than theoretical models.
3/ Multi-Modal Analysis: Combining high-frequency sensor data with variable-frequency event logs provides a comprehensive view of asset health. Feature clustering and dimensionality reduction techniques help identify which parameters truly indicate impending failures.
2. Implementing Remaining Useful Life Predictions
Traditional RUL approaches rely on manufacturer-defined safety thresholds. However, field data often shows significant variation—some components fail before reaching these thresholds, while others operate well beyond them. A more sophisticated approach uses fleet-wide failure data to build probabilistic models.
By applying similarity modelling to historical failure progressions, engineering teams can:
- Generate probability distributions for expected failure times
- Provide confidence intervals rather than point estimates
- Account for operating context and environmental factors
- Validate predictions against actual fleet behaviour
This data-driven RUL methodology proves particularly valuable for inventory management and maintenance scheduling, enabling just-in-time parts ordering and optimal resource allocation.
3. Addressing the Explainability Challenge (explainable ai)
While machine learning models can achieve high accuracy in failure prediction, their “black box” nature often creates adoption barriers among maintenance teams. Effective implementation requires explainable AI that provides:
a/ Feature Attribution: Understanding which sensor readings or event patterns triggered an alert helps technicians validate predictions and builds trust in the system.
b/ Historical Context: Showing similar past cases and their outcomes allows experienced technicians to apply domain knowledge in evaluating predictions.
c/ Natural Language Summaries: Generative AI can synthesize complex multi-source data into clear explanations, reducing the cognitive load on maintenance teams while preserving technical accuracy.
4. Practical Implementation Considerations for a platform to do Predictive Maintenance for Airports
For reliability teams evaluating predictive maintenance systems, several factors determine success:
a/ Data Quality Over Quantity: Focus initial efforts on assets with complete, high-quality data rather than attempting enterprise-wide deployment immediately. Disparate data like Event logs also provide rich insights similar to raw sensor data when properly analysed.
b/ Iterative Deployment: Start with high-impact, well-understood failure modes before expanding scope. Early wins build organisational confidence and provide learning opportunities.
c/ Integration Architecture: Modern predictive maintenance platforms should integrate via APIs with existing CMMS and ERP systems, avoiding data silos while leveraging current investments.
d/ Model Validation: Establish clear metrics for model performance, including not just accuracy but also lead time, false positive rates, and maintenance cost impact.
The Path Forward for monitoring with predictive maintenance for airports
As airports face increasing pressure to maintain ageing infrastructure while improving reliability, predictive maintenance offers a proven path forward. Success requires moving beyond vendor-specific solutions to platform approaches that can adapt to changing equipment, incorporate new data sources, and continuously improve through feedback loops.
For engineering managers, the focus should be on building data-driven maintenance cultures where predictive insights augment rather than replace human expertise. By combining advanced analytics with domain knowledge, airports can achieve the optimal balance between asset reliability, maintenance costs, and operational performance.
The technology exists today to transform airport maintenance from reactive firefighting to proactive optimization. The challenge lies in thoughtful implementation that respects both the complexity of airport operations and the expertise of maintenance teams.
Amygda provides a platform to shift towards predictive maintenance for airports
Discover how our advanced monitoring techniques and predictive maintenance platform can support your airport BHS reliability metrics. Connect with our engineering team to discuss your specific failure modes and data architecture. Email me at [email protected] to have a chat.


